博客内容使用 CC BY-NC-SA 3.0 授权发布。
Powered by Hexo & SimpleBlock .
决胜延迟的最后一公里
这是 1 月 16 日在公司准备的一次技术分享的 PPT 和讲稿,考虑到 PPT 文件或者视频不容易被浏览引擎索引所以整理成一篇博客供大家参考。

大家好,欢迎各位来听这次分享。今天我分享的题目是“决胜延迟的最后一公里”。

我们大家都知道网站打开的速度严重关系着用户体验,根据 akamai 的一份报告显示,有约 50% 的用户会在等待页面加载 4s 后放弃访问,有 25% 的用户期望页面在 1s 内打开。各大厂商也都有类似的数据验证了这一点,当打开延迟增加时,用户的耐心也会大大降低,从而直接影响访问量甚至是收入下降。
那么我们应该怎么去提升用户访问速度呢?这个访问速度跟什么有关?
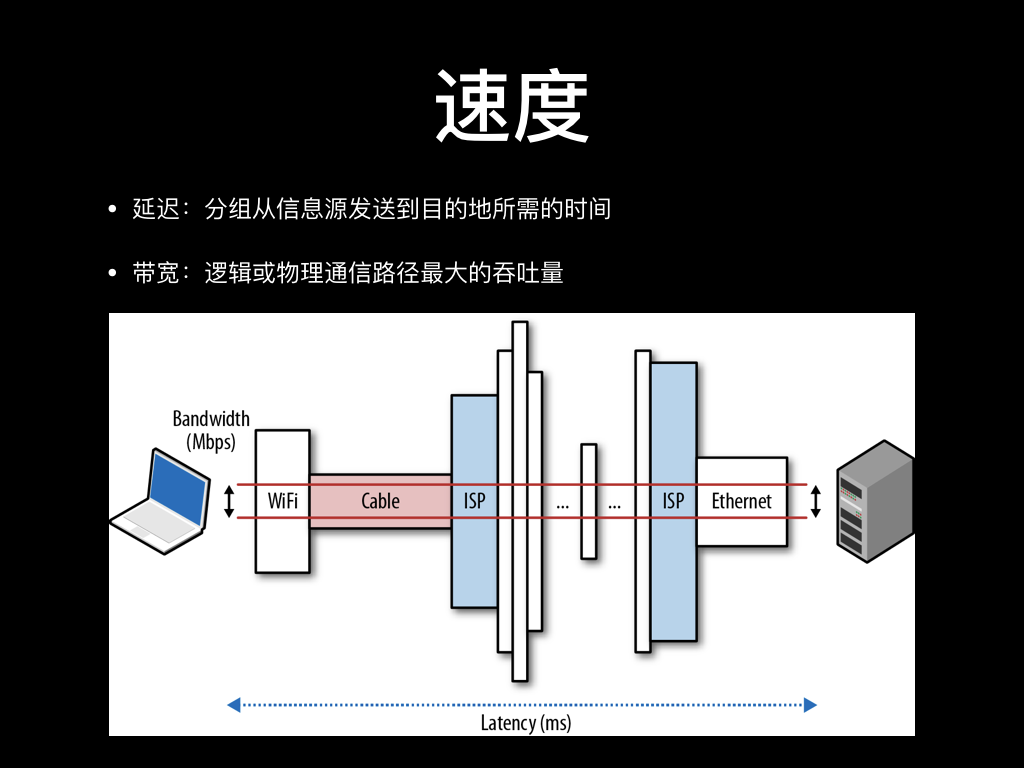
用户访问的速度跟很多因素有关,特别是请求到后端服务器以后,后面可能还要访问多层存储、程序内可能还有很多计算才能返回。但这其中的只看网络的速度的话,我们主要看两个因素:
一个是延迟,是数据分组从一端传到另一端所花的时间。这个时间主要跟两端的距离、传输介质、线路拥塞情况等因素有关。比如光的传播速度是 30w km/s,一般的玻璃的传输折射率是 1.5 的样子,换算下来光在光纤中的传播速度是 20w km/s。北京到深圳的距离与约 2000 km,那理论时延就是 10ms,但实际上我们 ping 到深圳的服务器去一般都要 40ms 的样子。这中间还有折射后实际传输距离改变、线路的实际架设距离、不同的运营商之间的互联互通等等问题。一般来说,我们很难定义好说一个地区访问另一个地区时延就是多少,我们心中可能有一个经验值,但它可能也会时时变化。
第二个是带宽。这个应该好理解,如果传输的所有中间环节都是串行的话,那带宽就是中间传输环节最窄的部分。但实际上大部分带宽的限制出现在靠近用户这一侧,上限一般就是网络运营商在路由上设的限制,或者是因为用户这边最后一公里传输介质不稳定导致带宽甚至达不到运营商的限制。
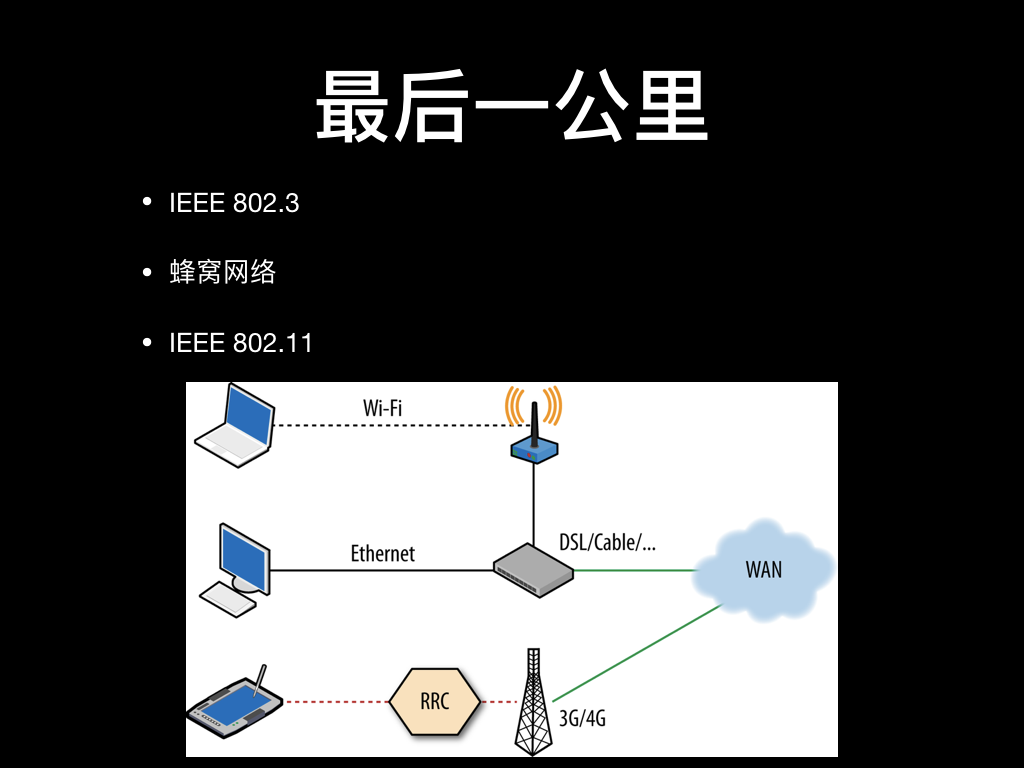
我们回应一下标题,来看一下什么是最后一公里。通信领域中的最后一公里指网络运营商机房交换机到用户设备的连接,也就是我们上一幅图中画的用户设备到 ISP 的相关连接。
最后一公里的接入方式最常见的有三种:
一种是以 IEEE 802.3 协议簇为代表的以太网,他们主要通过双绞线铜缆或者光纤连接,最高理论速度可以达到 100G bps。通过物理线缆连接的以太网很稳定,除了少量的电磁干扰外基本没啥需要特别注意和担心的。使用得当的话,以太网的速度还是有保证的,这也不是我们今天讨论的重点,我们先跳过。
第二种是以 IEEE 802.11 协议簇为代表的 WI-FI 网络,一般是在以太网上接一个无线路由器然后在 2.4GHz 到 5.8GHz 的频段上广播无线电信号,客户端跟它连接认证再传输数据。这里面会有很多原因导致数据传输不稳定,有延迟升高和带宽降低的现象,稍后我们来一一分析。
第三种是最常见的手机联网方式,全称是蜂窝式移动通信网络,从大家熟知的 2G 到现在的 4G 都是。最开始的移动网络架构上是将基站的分布设计成蜂窝的样子, 但因为技术迭代、用户分布和现实选址考量等等原因,我们现在的 2G、3G、LTE 网络已经不像“蜂窝”了,但为了习惯,大家现在一般还是这么称呼。蜂窝网络的架构在不断迭代和调整,延迟和带宽问题也在不断改善,但总体来说蜂窝网络架构下设备的联网方式跟以太网和 WI-FI 网络差异还是很大,后面我们再来具体分析。
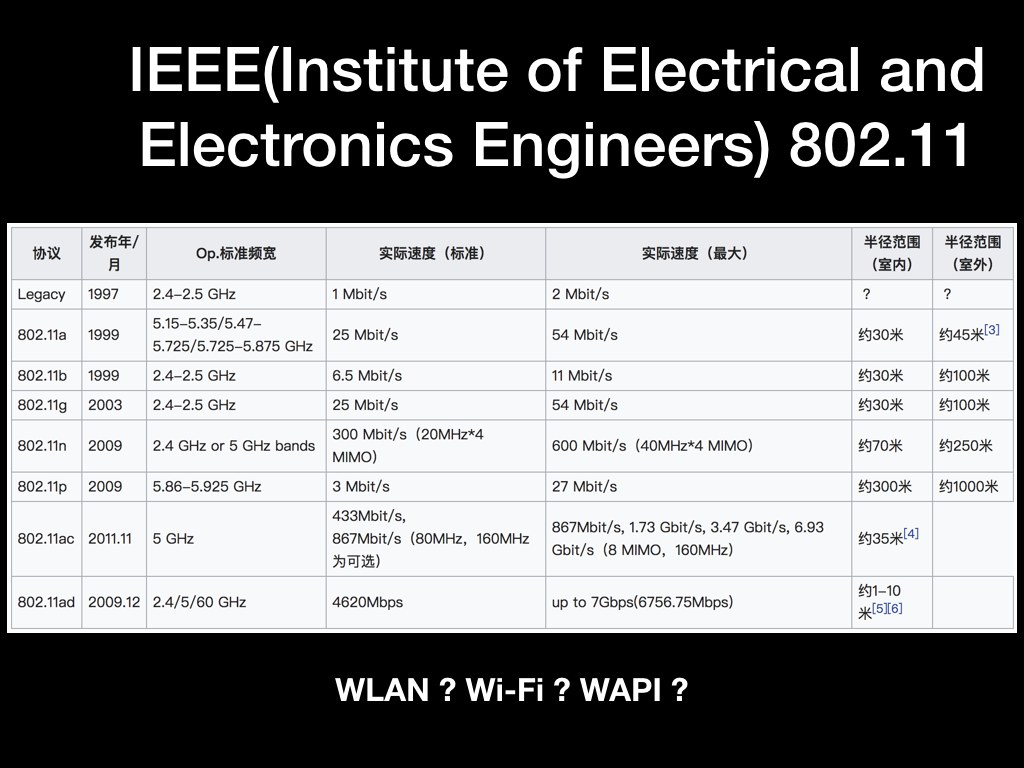
我们首先看一下 IEEE 802.11 协议簇。IEEE 是电气电子工程师学会,是世界上最大的专业技术组织之一。他们在 1997 年为无线局域网制定了第一个版本标准 IEEE 802.11,之后在 1999 年在这个协议上新增了在 2.4GHz 频段工作的物理层叫做 802.11b。因为 2.4GHz 频段是世界上绝大多数国家都开放使用的公共的频段,所以 802.11b 马上就火了。
延伸一下,其实频段资源还是非常稀缺的。各国都出台无线电相关的法律法规集中管理和审批无线电频谱资源,通信公司往往都要花大价钱去买频段,比如美国的 700MHz 频段的使用权卖了 196 亿美元。大家能够自由使用的频段不多,刚好 2.4GHz 就在其中。
因为 IEEE 是一个技术型组织,并没有充足的人力、物力去推广 802.11b 协议。所以在 1999 年各厂商就联合起来成立了非盈利性的组织叫 WI-FI 联盟,负责测试和认证这些设备,设备能兼容的 802.11b 协议的就给它们打上 WI-FI 的 logo。后来还有不断的改进,新增了更多的频段、提升安全性、提升覆盖面积和传输速率,目前使用最广泛的标准应该是工作在 2.4GHz 下的 802.11n 和工作在 5GHz 下的 802.11ac。随着 802.11 新的标准和频段的使用,以及移动设备数量的迅猛增长,人们逐渐将 Wi-Fi 和 IEEE 802.11 整个协议簇等同起来,甚至和无线局域网络等同起来,严格意义上来讲是有一定区别的。
再讲个小故事。无线局域网 WLAN 的全称是 Wireless Local Area Network,实际上描述的是一种无线的组网方式。IEEE 802.11 协议簇是实现 WLAN 组网的其中一种最常见的标准,还有一种不常见的标准是 WAPI,全称很长我就不念了。这是中国政府在 2003 年发布的一种 WLAN 标准,随后工信部在国内强推 WAPI,2004 年发布禁令:禁止销售带有 Wi-Fi 模块的产品、带无线局域网的电子产品必须支持 WAPI。如果大家用手机比较早的话可能会有印象,那时候大家都会通过各种渠道找水货手机用,因为没有阉割 WI-FI 模块。现在国行 iPhone 和国内的 Android 手机上的显示还是无线局域网,港版或者美版的其他手机可能就直接显示的是 WI-FI,这也就是说这些手机现在还是同时支持了 WAPI 协议的,虽然你可能找不到一台支持 WAPI 协议的路由器。

背景大致介绍了一下,我们回到正题来。
无论使用哪种无线技术,所有通信方法都有一个最大的信道容量。这个容量是指信道在单位时间内可以传输的最大信号量,实际上描述的就是我们通常意义上的带宽。信息论之父克劳德·香农对信道容量给出了一个确切的数学模型,这个模型有着具体的传输技术无关性。
从这个公式中可以看到左边的 C 是信道容量,右边的 B 是可用带宽, S 是信号功率,N 是噪声功率。
其实这个公式也符合直觉,总共有三种情况:
- 当信噪比不变的情况下,提升可用带宽 B 能提升信道容量。
- 当发射功率 S 和可用带宽 B 不变的情况,噪声功率 N 越低,信道容量越高。
- 当噪声功率 N 和可用带宽 B 都不变的情况,增加信号功率 S 可以提升信道容量。
这里面实际对应了我们常见的 WI-FI 信号优化的思路:
- 买个更好的支持理论速度更高的路由器,算是提升可用带宽
- 将路由器发射信道换到干扰较少的信道,算是降低噪声功率
- 买信号放大器增大信号发射功率,是提升信号功率
如果要提升可用带宽达到协议的上限速度,一般需要选择路由器支持到较新的协议。比如 2.4GHz 下 802.11n 协议的上限 300M bps,如果是换到 5GHz 的话 802.11ac 协议的上限就直接提到了 867M bps。
提升信号功率应该也好理解,一般就是离路由器太远了,发射功率太低或者是信号频率高 5G WI-FI 穿墙性能不太行,这种可以买信号放大器、尽量离路由器近点才能解决。
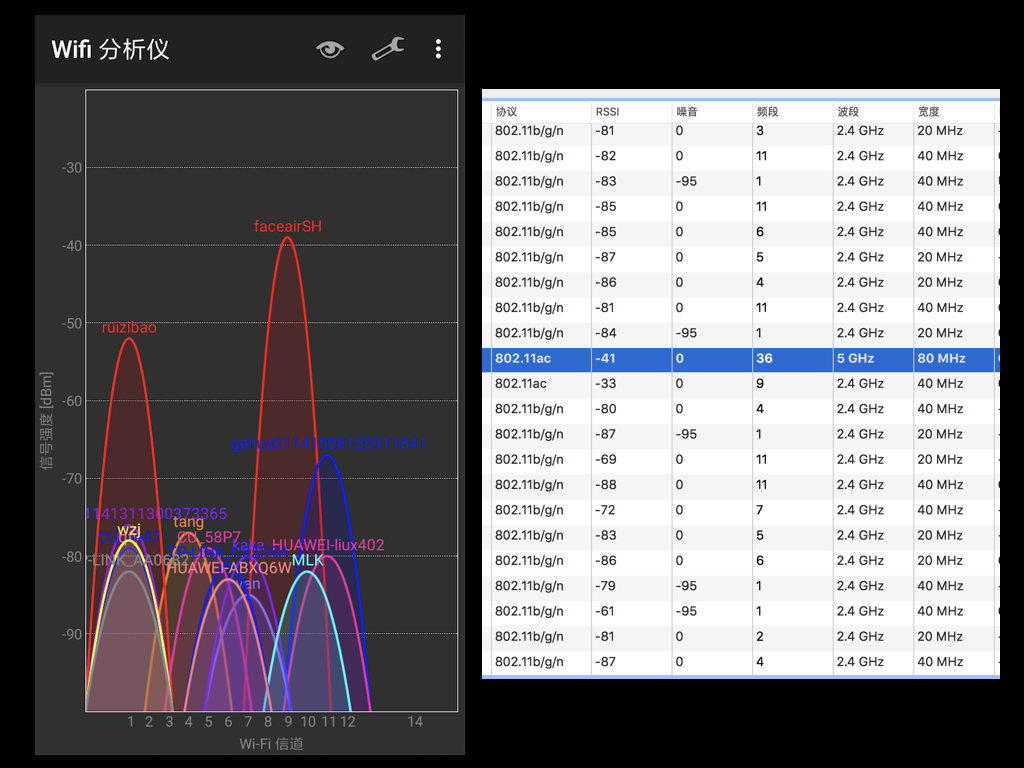
IEEE 802.11 协议设计的有参考 802.3 以太网协议,所以它们都有一个相同的特性,就是自我控制能力。以太网和 Wi-Fi 都把传输的媒介视为“随机访问通道”,即没有调度中心控制哪台设备在哪个时刻可以发送数据,所有设备都自我控制,协同工作,共同维护共享信道的性能。Wi-Fi 采用的是一种冲突避免机制,即每个发送方都会在自己认为信道空闲时发送数据,以避免冲突,当发生信道冲突时,随机一段等待时间再进行重试。换一句话说,如果你跟邻居的路由器使用了同样的信道,而且他正在看高清直播,你们传输数据的时候发送冲突,那你的带宽可能就会减至一半,甚至还不到一半,这就是 WI-FI 的冲突避免的 feature。如果你自己要检查是否有干扰的话,一般在电脑上 ping 一下无线网关就能确认延迟和丢包率。
所以如果是要减少冲突减少噪音,那就需要使用这个信号频段内的电子设备越少越好。首当其冲要看的就是工作在同一频段的其他路由器,比如 2.4GHz 下的 IEEE 802.11 协议簇下的大部分协议都分了 13 个信道,它们的中心频率不同,但都占据了一定的频率范围,信道也会有一部分是重叠的。如果大量的路由器都使用了相同的频率,就会产生上面图这样的效果。另外常见的电磁炉和蓝牙也是工作在 2.4GHz 下,他们工作的时候也可能就会干扰 2.4G WI-FI 工作。
5GHz 的路由器信道各个国家划分标准不太一致,但总体来说可以用信道更多,有效频率范围也能达到更高,目前还不太拥挤。同时因为 5G 信号频率高传播衰减快,也不太容易干扰到别人,右边图可以看到我家附近能收到 5G 信号的路由器就只有我的一个,就不用太担心干扰啦。

OK,那我们最后来总结一下 WI-FI 网络的特点:
- 因为冲突避免策略,所以不能保证带宽和延迟
- 因为不同环境下信噪比差异很大,所以带宽无法预测和保证
- 根据国家颁布的《无线电管理条例》来说 5G 频段的发射功率限制在 200mW 以内, 2.4GHz 频段发射功率限制在 100mW 以内,很多放大器强行增加信号发射功率其实违法
- 信道频宽重叠刚才有描述
- 大家也有经验,大型会场的 WI-FI 无线信号很难保证,其实有一部分原因就是客户端发射频率一致互相干扰导致的
最后总结一下,就是不同环境下的 WI-FI 网络差异很大,很难保证带宽和延迟,所以速度也很难预期

最后一种最后一公里的通讯方式是蜂窝网络,它跟 WI-FI 一样都是通过无线电波传播,但也有很大的差异。
蜂窝网络的不同制式工作在不同的频段上,比如常见移动、联通、电信的 4G 制式 FDD-LTE 和 TDD-LTE 分布在 1600MHz-3800MHz 的频段上,跟 WI-FI 最大的区别是各运营商的频段是早就分好了,信号干扰较少。而且根据《无线电管理条例》的规定不允许其他人在这些频率上发射信号。
根据刚才的香农公式分析,当噪音功率固定而且很低的时候,影响信道容量的就只有信号功率和可用带宽两个因素了。2G 到 3G 到 4G 制式的升级会带来可用带宽的提升和延迟的大大降低,所以升级到最新的网络制式是一个很好的提速办法。
另外一个信号功率跟两个因素有关:一个是用户设备到通讯基站的距离,另一个是运营商使用的信号发射频率。
第一个到基站的距离好理解,运营商也通过架设更多的基站来增强用户设备收到的信号功率。
第二个信号发射频率怎么理解呢,一般我们知道无线电频率越高理论带宽越大但信号衰减也越快,频率低一点可以获得更大的覆盖范围。在 2G、3G 时代运营商使用了更低的发射频率,比如 2G 工作在 800-900 MHz,能获得很广的覆盖范围,同时问题是上网速度不怎样。到 4G 时代,信号发射频率升高覆盖范围变小,必然需要架设更多的基站,带来的是高额的成本。
而实际上 4G 协议规定的还有个 700 MHz 的频率是可以使用的,也就是我们刚才说过的在美国卖了 196 亿美元的频段,这个频率在中国是分给了广电总局的。广电又没有能力利用起来,各家运营商都非常眼红,如果他们能拿到这个频率的使用权,那在一些偏远地区支持 4G 可以少架基站,这些地方因为人少也不需要非常高的带宽,能减少大量的成本。前两天还看到有新闻说广电要拿这个 700 MHz 频段的使用权换联通的股份,感觉有点略流氓。
好了,说回来。除了自己找运营商升级网络制式,再等运营商架基站外,还有影响移动网络速度的因素吗?
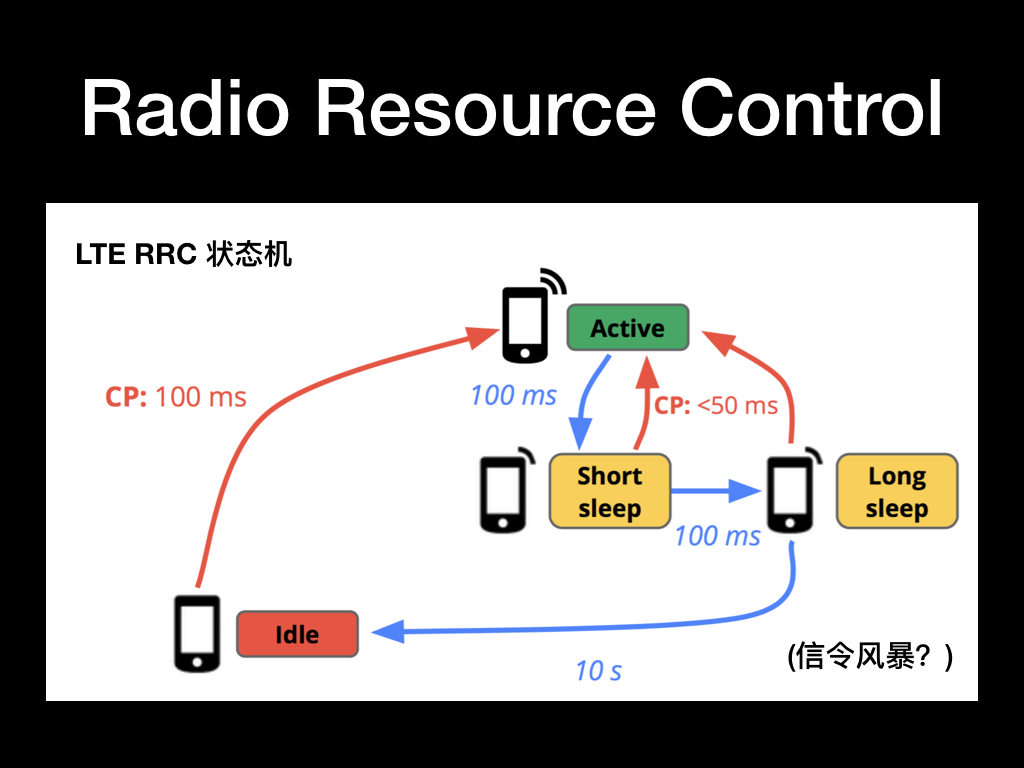
还有一个非常重要的因素就是 Radio Resource Control,简称 RRC,翻译过来就是无线资源控制。RRC 全权负责设备在什么时候能发射信号,带宽多大,功率多少,以及监控设备的电源状态等。简而言之,RRC 就是无线电网络的中枢。想要通过无线信道发送数据?你必须先向 RRC 申请无线电资源。想要接收互联网上的数据?RRC 会通知你什么时候监听接收到来的分组。
为什么要有 RRC 这么一个机制呢,主要是为了省电。无线电在任何手持设备中都是最耗电的组件之一。要说最耗电,应该是点亮的屏幕,但在实际使用中,屏幕一般情况下都是熄灭的,反倒是无线电组件,为了让用户有“永远在线”的体验,必须一直运行。
实现这个目标的一种方式就是让无线电组件不停地工作,可这么干会疯狂地消耗电量,用户设备的续航完全没法保证。而且 3G 和 4G 的最新版本要求并行传输,这相当于同时开启了多个无线电组件,同时考虑到要覆盖更大范围以及排除干扰,这两个网络在通信时要求的最高功率甚至会达到 1000~3500 mW。
所以一直工作很难达到,所以通过 RRC 来通知设备什么时候启用无线电组件,什么时候休眠无线电组件。
上图中描述的是 LTE 制式下的 RRC 状态机,其他制式下可能略有差别,但大部分的原理还是共通的。当设备要准备传输数据了先要通过 RRC 申请资源,等确定可以发送数据了开启无线电组件,等待一段时间都进入短休眠状态,再等一段时间看情况进入活跃或者长休眠状态。这个描述的长短休眠状态下无线电组件实际也是耗电的,只不过不是满载运行功率会略低一点,最后如果不需要发送数据了等待 10s 释放所有的资源进入空闲状态。也就是说每发送一次数据都会至少激活无线电组件 10s 的时间,如果设备频繁被唤醒发送数据,就可能造成电量的大量消耗,我们的客户端编程中也需要注意这一点。
剩下的我们来聊一下信令风暴吧。大家以前应该听说过微信信令风暴的传闻,当时听说运营商约谈了微信,要对微信收取费用,还有传言微信要把这笔费用转嫁到用户身上,为什么会发生这样的事情呢?通过我们刚才的分析,应用要发送一次数据要通过 RRC 指令申请无线信道资源,RRC 的协议还要经过几个 RTT 的握手,基站要和后面的网关要为请求准备资源,实际上消耗还是挺大的。等连上以后,微信收发几个数据包确认没有新的消息马上就休眠了。当微信的用户量变大了以后,应用的心跳太频繁,运营商基站不堪其扰,信令太多了超过了能承受的负载。而且严格来说运营商的线路和无线电信道是一种分时系统,不同的用户间交替使用,本来是应该按占用和使用时间来收费的,但现在运营商是按流量来计费,心跳包体积很小微信的使用的流量又上不去,传闻是微信占用了中移动 60% 的信令资源,但仅带来 10% 的移动数据流量,导致运营商也很头疼。后来微信主动降低了心跳包的频率,运营商也开始升级基站配置这事就算不了了之了。
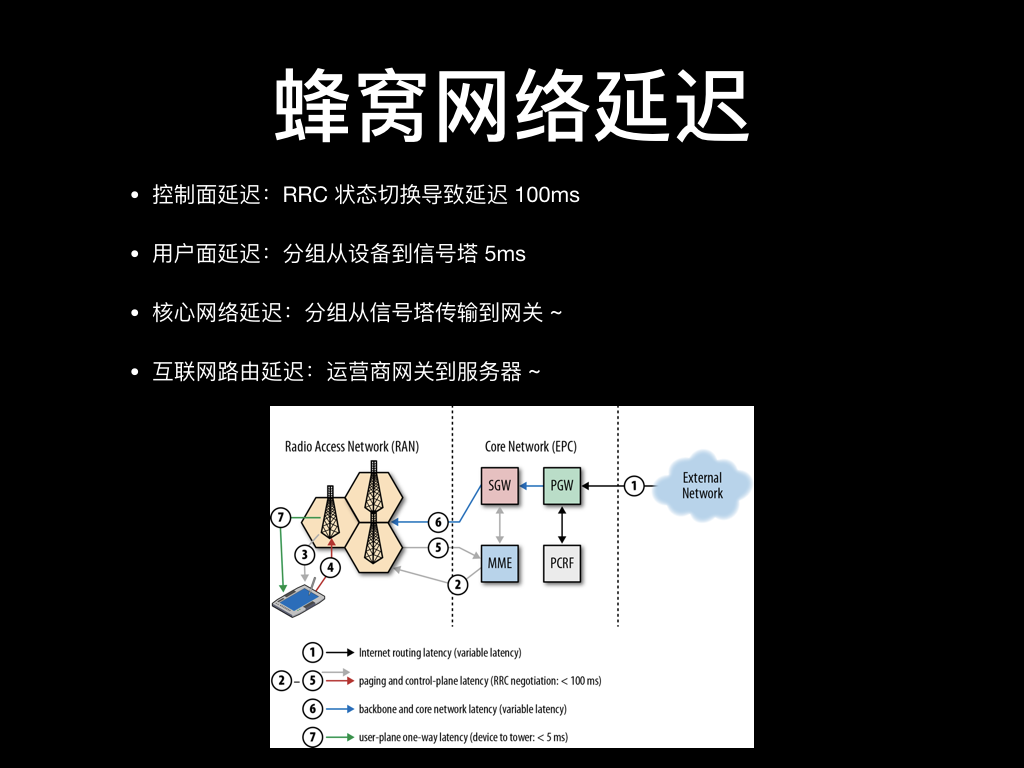
刚才既然说到 RRC 要握手,那自然也是需要消耗时间的。4G 网络的 RRC 状态从空闲切换到活跃状态最低要用 100ms,这个切换延迟我们称为控制面延迟。
为什么要说是最低 100ms 呢?当基站繁忙的时候 RRC 有可能会拒绝你的状态切换请求。大家可能会有经验,在人员过于密集的场所,手机可能会上不了网,这就是无线信道资源配额已经用完了,RRC 把你的状态切换请求拒绝了。
另外的还有用户面延迟是指分组到信号塔的时间,一般小于 5ms,但如果信号功率不够或者受到的无线电干扰严重可能会发生重传无法准确保证时延。前面说的 4G 信号频率高衰减快,在地铁上或者基站覆盖不太好的地方,信号很可能已经衰减到没有了,手机就只能 fallback 到 3G、2G 上,2G 频率低衰减慢所以总是有信号,如果信号回落到 2G 了延迟就更没法保证了。
最后分组再从信号塔传输到网关再传到具体的服务器,这个的时延因具体的运营商线路不同而不同,也不太好统一描述。
所以总结一下蜂窝网络在第一次发起请求或者空闲超过 10s 无线电模块休眠后发起请求的时延可能无法保证,因为中间 RRC 状态切换时间无法预期,建立连接后的传输时延要看信号功率的强弱以及运营商线路才能确认。
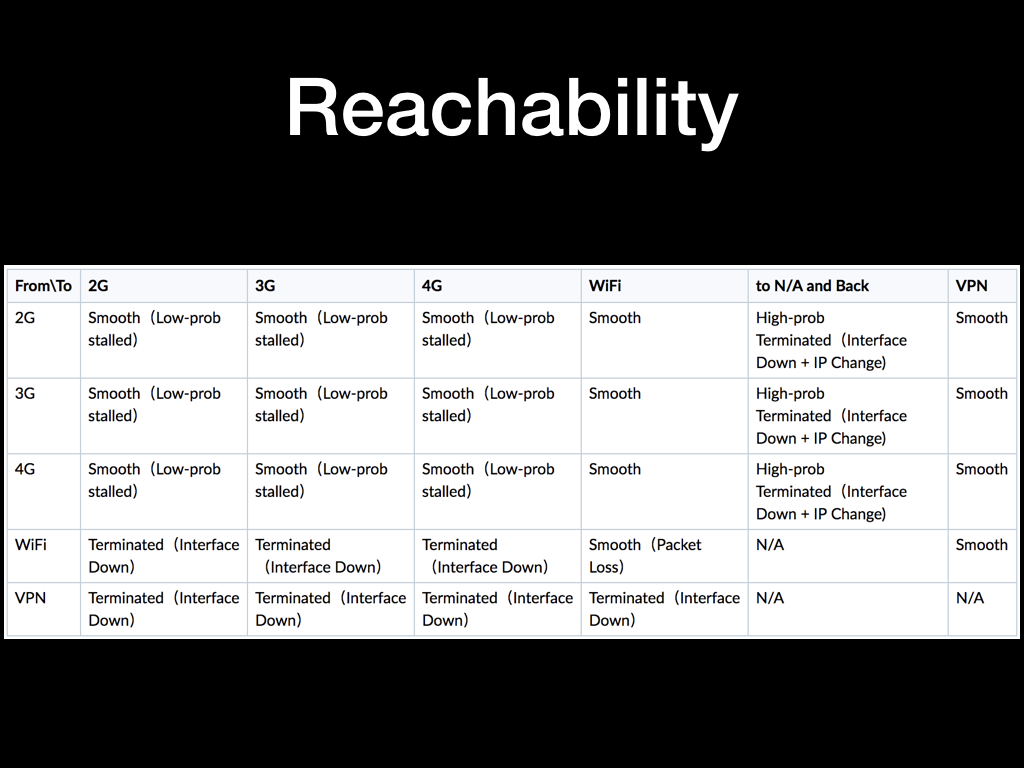
前面我们分别介绍了两种无线通讯方式,还有一种情况是这些通讯方式互相地来回切换。在正常的使用中我们可能比较少切换网络,但如果对这种临界状态处理的不好的话,很可能会出现一些奇奇怪怪的问题。
上面图中介绍了一些常见的网络切换情况下网络的表现。
简单的描述是手机上的移动网络是一直保持活跃的,当连接上 WI-FI 后,虽然默认网关指向 WI-FI 热点的 IP, 但已建立的连接依然走 4G 网络,不受影响。
但如果连接是在 WI-FI 网络下创建的,当断开 WI-FI 以后网口会直接 down 掉,热点 IP 也连不通了,所以当 TCP 连接再有数据传输的时候会收到 reset 包,需要应用重新建立连接。
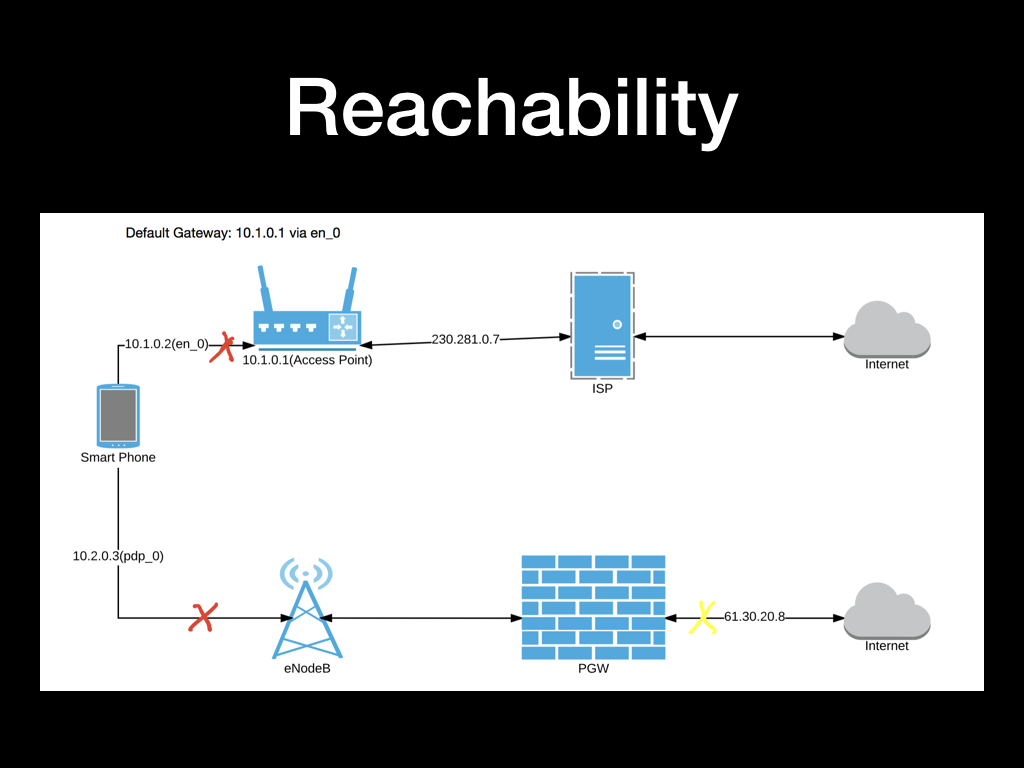
再给大家介绍两种特殊情况:
- 理论上当和基站通讯中断一段时间内,RRC 会话和 IP 租约都会保持,这个时候恢复信号或连接新的基站,甚至在 2G、3G、4G 之间切换都不会因此中断。但实际能否保持连接,取决于基站附近移动设备数量。我跟江泽在六道口地铁站测试信号中断时,除中午时间容易保持连接外,下午 3 点到晚高峰都会 100% 链路关闭或者 IP 变化。
- 当出现高丢包,但链路并未关闭时,如果对方认为手机已发呆超时,会主动关闭连接,图中黄叉情况。此时运营商网关会认为连接已关闭,停止进行 NAT 服务。信号恢复时。客户端 TCP 会认为连接依然存在,但此时发送的任何数据都会被网关丢弃。应用表现为连接还在,但无响应,客户端开始无限转圈圈,不会收到任何错误。

所以呢,客户端在编程的时候要处理处理好网络切换的状态。
一般 iOS 和 Android 客户端上都有相关的 Reachability API,可以监听相关网络切换的事件发生,然后新建一条连接并对正在进行的幂等网络请求进行安全地重试,这样可以做到尽量平滑的过渡。
另外可以开启 TCP_KEEPALIVE 选项,允许 TCP 协议栈对连接进行保活,可以尽快发现死连接。
应用层的超时时间也需要梳理一下,避免无限等待,该重建连接重试的时候就果断重试就好了。

最后我们总结一下。我们刚才着重分析了最后一公里的两种无线通讯方式,一种是 WI-FI 网络,另一种是蜂窝网络,这两种也是移动设备最常见的上网方式。
它们有着这样的特点:因为信道干扰和冲突避免策略,WI-FI 网络的延迟和丢包可能在毫秒级到秒级,丢包率可能有非常大的波动,带宽也无法保证。蜂窝网络因为 RRC 机制、信号功率和制式的降级的不确定性也无法保证延迟和带宽。
总而言之,我们应该明确一点:移动网络有着非常多的不确定性,不同的用户所处的环境下网络状态难以保证。我们在设计产品的应该充分考虑到这一点,不要对用户的移动网络稳定性做过多的期待和假设。
可能大家对我说的说的这些没有感触,我们在北京可能平时的信号都还挺稳的,甚至在地铁里都能保证全称 4G 连接,但并不是所有的地方的基础通信设施覆盖都这么全,网络都这么稳定。比如我们站上的学生用户们,他们在宿舍一层楼可能有大量的路由器工作在同一频道上,可能校园网禁止路由器拨号只能用电脑软件来发射 WI-FI 信号,甚至出口带宽也是共享的,这些情况下网络的质量很难说;而运营商网络,比如联通的互联网套餐开始普及了以后很多地区的基站是超负荷运转的,RRC 的切换时间很难保证,信号满格但就是上不了网等等情况。
如果我们想让 App 在各种网络情况下都能快速加载,那针对弱网条件的适配是必不可少的。那我们在考虑优化客户端在移动网络下的性能的时候,能做的优化有哪些呢?
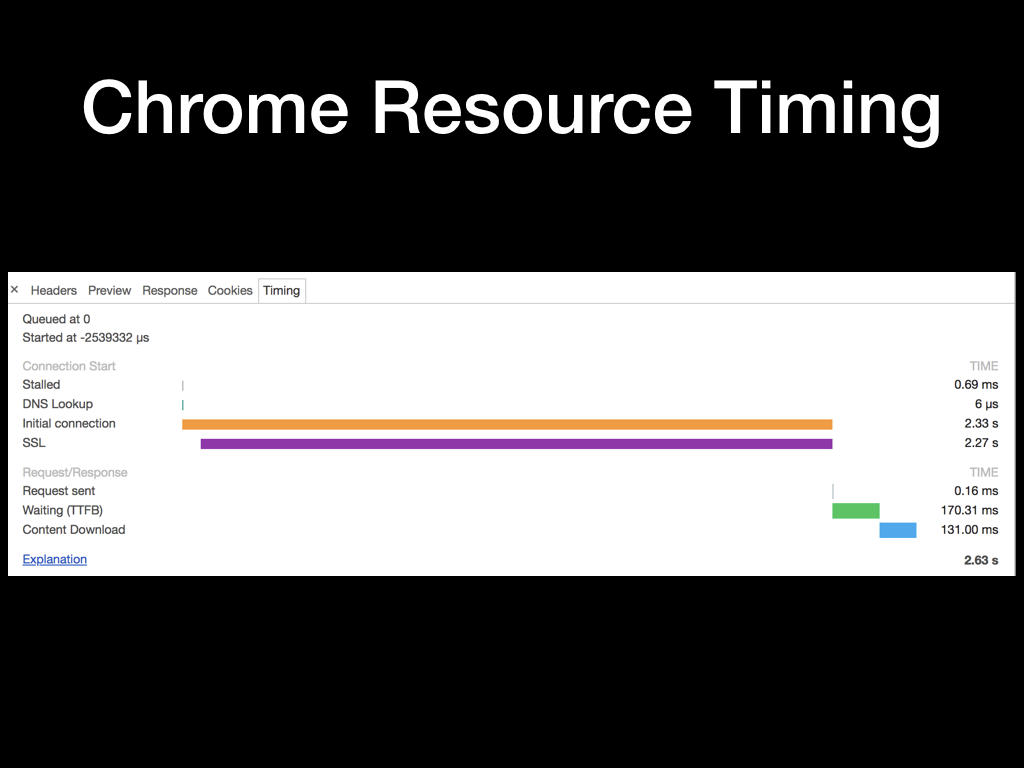
我挑了一个 Chrome 加载资源的一个时序图,用来展示一个完整的 HTTP 请求所需要的过程。在不同的平台下可能略有差异,但总体来说都是差不多的,那我们就以此分析一下。
因为并发限制,请求会有一个入队等待的过程,我们看到的这个请求等待了 0.69ms。然后紧接着是进行 DNS 查找,因为命中了 Chrome 内建的 DNS 缓存,所以这个时间只花了 6us (微秒)。再然后是初始化连接花了 2.33s,其中大片的时间是在进行 SSL 握手。请求初始化完毕后,客户端发出请求,花了 0.16ms。这个时间为什么这么短呢,因为这个是表示的浏览器将 HTTP 协议请求数据通过系统调用传给了 TCP 协议栈,存到 TCP 的缓冲区的时间,并不代表 TCP 将所有的数据都成功发送出去了。所以后面的等待时间是略有误差的,TTFB 的全称是 Time To First Byte,表示收到服务端返回的首字节的时间。最后一个时间分片表示浏览器接受到完整的 HTTP 响应所花的时间。
这些过程其实大家可能都理解,那么我们应该采取哪些措施去优化这些传输的中间过程?
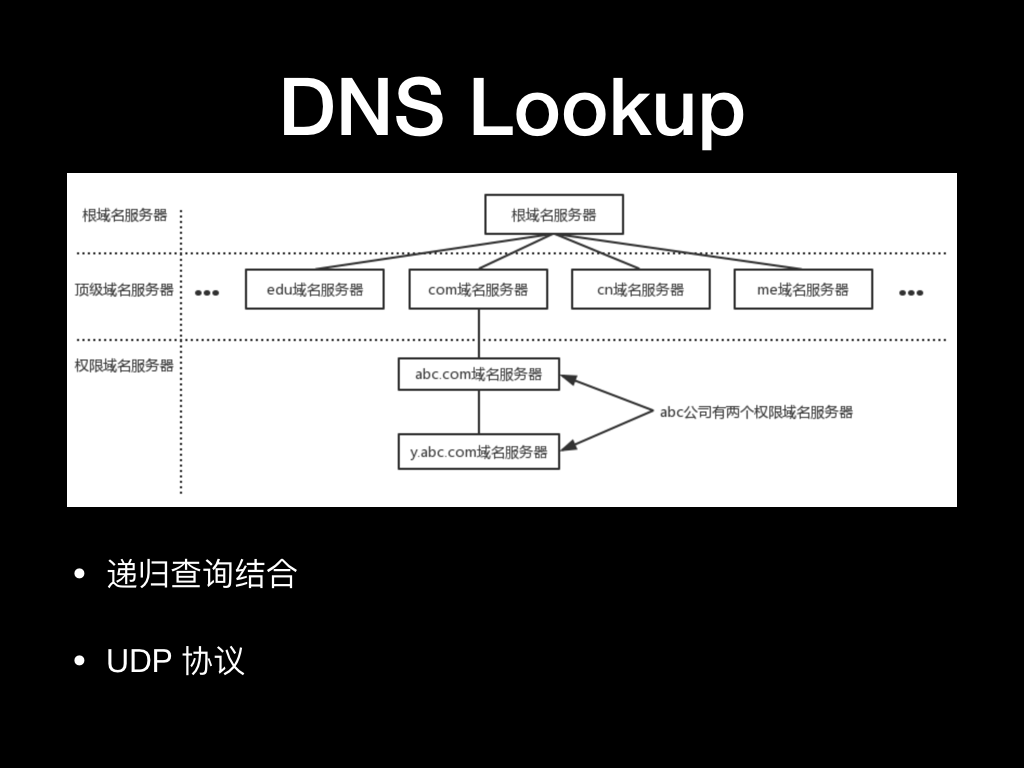
我们首先来看一下 DNS Lookup 过程是怎么完成的。
如果没有命中应用内建的 DNS 缓存,那么应用会向操作系统会发起一个 gethostbyname 系统调用,然后操作系统会准备好 DNS 查询的报文通过 UDP 协议发给本地 DNS Server。本机的 DNS Server 的是在获取本机 IP 的时候从上级 DHCP 服务拿到的,蜂窝网络下是通过 APN 配置拿到的,这个 DNS 一般是给你提供网络的运营商提供的。然后 DNS Server 会从根域名逐级递归地找到你的域名服务器然后再查询到你访问域名的目标 IP。这中间 DNS Server 的递归查询环节多耗时非常的不可控,而 gethostbyname 的系统调用本身即没有提供超时控制,也控制不到 DNS Server,所以一般在应用层做的超时设置粒度非常粗。
另外我们在前面讨论提到了,无线网络可能丢包率和延迟都高。而 UDP 协议本身是不会重传的,如果中间环节发生了丢包,这边要等到应用层的超时之后才能觉察和重试,非常的迟钝。
另外还有一个问题是运营商故意的劫持或者是技术问题常常会导致他们维护的本地 DNS Server 解析到错误的 IP,这种解析失败不一定会覆盖到别的网站,用户体验上可能就觉得就是我们的网站挂了,也没有动力第一时间去找运营商投诉。
那么有什么办法杜绝这些问题吗?

业界常见的方案大概有两种,一种是 HTTPDNS,另一种是通过一个固定 IP 的机器下发各域名全量的 IP 列表。
我们目前是使用的阿里的 HTTPDNS 方案,DNS Server 由阿里提供和维护,相对于依赖全国各地的运营商,阿里提供的企业服务会更加可靠一些,TCP 协议也有分组级别的重传相对会更加可靠一些。
另一种直接下发 IP 列表跟 HTTPDNS 比较类似,区别是自己来维护,同时解决单点故障的时候这种客户端级别可以直接 fallback 到其他节点会更灵敏和健壮一些。
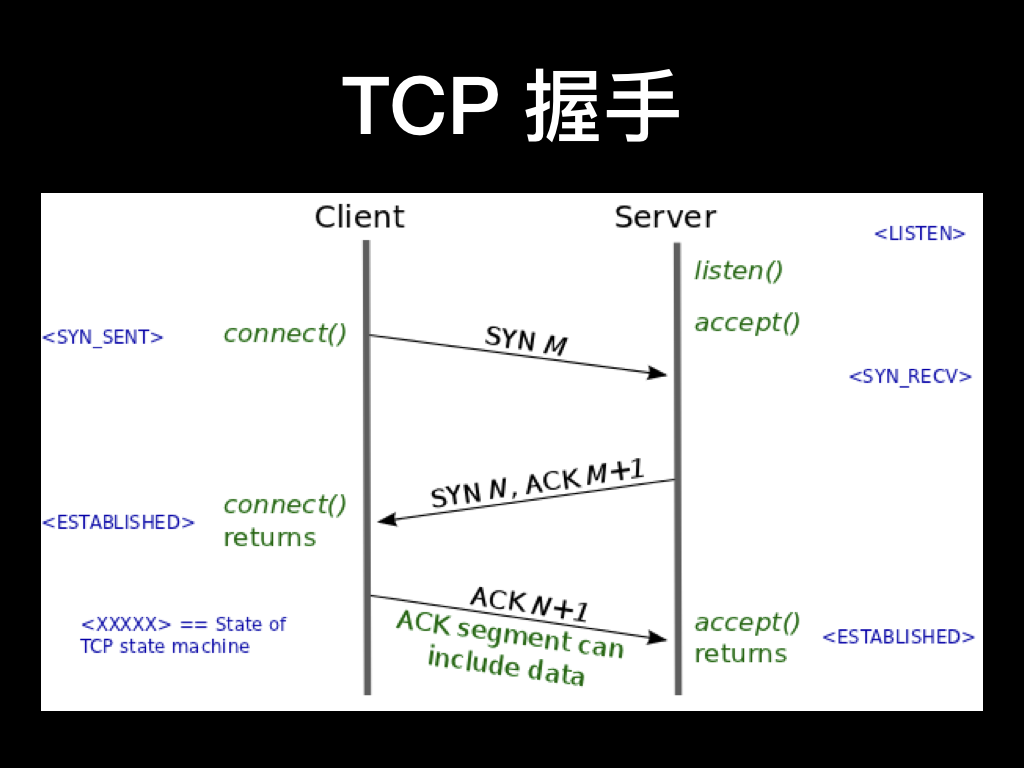
DNS 的问题说完了,接下来要通过 TCP 协议建立连接了。
所有 TCP 连接一开始都必须经过三次握手。客户端与服务器在交换应用数据之前,必须就起始分组序列号,以及其他一些连接相关的细节达成一致。出于安全考虑,序列号由两端随机生成。一般至少需要一次 RTT(Round-Trip Time,往返时间),后面客户端再 ACK 的时候就可以带上数据了。
但是根据我们的编程习惯,如果是使用阻塞 socket,在连接完成之后 connect 调用才会返回才能向 socket 中写入数据。或者如果是设置为非阻塞 socket,我们需要在 connect 后立即往 socket 中写入数据才有可能在第三次 ACK 的时候带上数据,否则等连接成功的事件再写就迟了。所以第三次 ACK 时候带上数据这个 feature 其实比较难利用上。
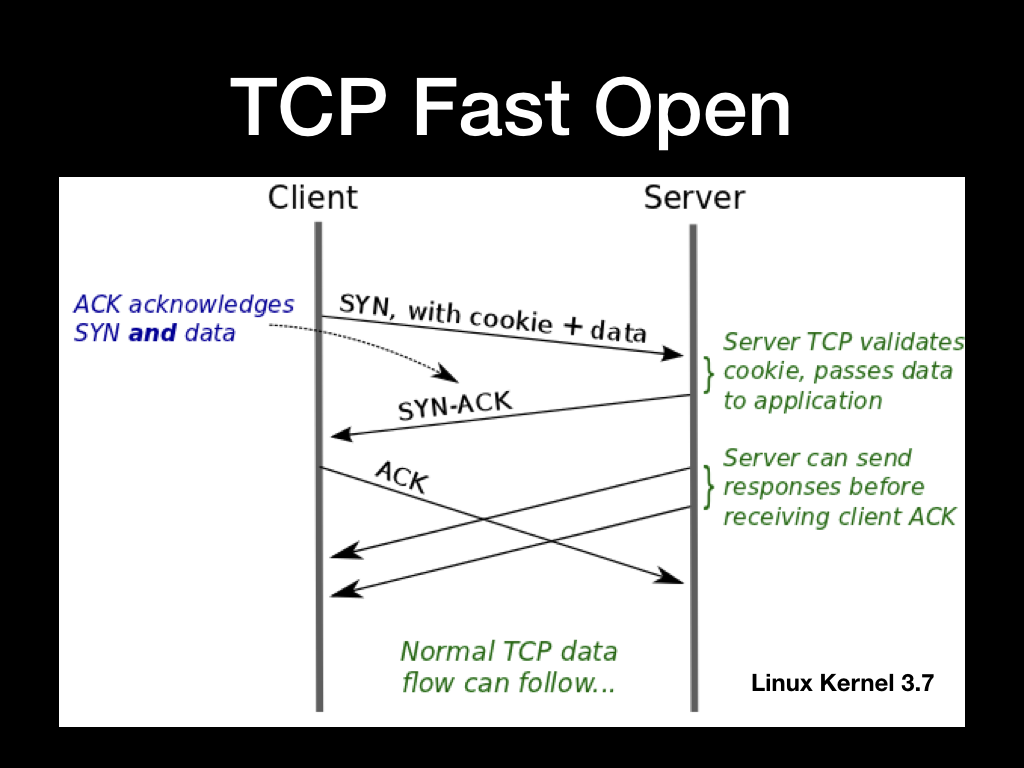
所以呢,为了在降低 TCP 握手时延的影响,也为了尽快开始发送数据。Google 的几位大佬提交了 RFC7413 对 TCP 对协议进行了拓展,支持了 TCP Fast Open 选项。Linux Kernel 在 3.7.1 之后已经支持开启 TCP Fast Open。
TCP Fast Open 的开启后握手的过程大概是这样的:
- 先使用普通的 TCP 三次握手建立连接一次,但是这个过程中 TCP Server 会分配一个 cookie 给 Client,Client 将这个 Cookie 保存起来
- TCP Client 使用 Cookie 构造 TCP Fast Open 握手包,这个时候正式开始 Fast Open 的流程
- TCP Server 对 Client 的 Cookie 进行验证,验证通过则正常交流,不通过则忽略
时延长而且不稳定的网络都建议开启 TCP Fast Open,类似的 Shadowsocks 的 Wiki 里也建议了开启 TCP Fast Open。
据我查到的资料是 TCP Fast Open 在 iOS 9 开始支持,Android 端受限于 Kernel 的版本目前还只有部分手机支持。已知的有 Chrome 浏览器在各端的 App 上的 TCP 协议栈都是他们自己做的,所以能方便的开启 TCP Fast Open。而 Server 端开启 TCP Fast Open 也不是太方便,知乎现有的后端与客户端通讯的网关和 CDN 节点都不是自建的,也要依赖多家第三方服务的供应商来开启。所以这个特性也不是太好利用起来。
说完了 TCP Fast Open 我们再来看一下 TCP 的拥塞控制,这里我简述一下 TCP 拥塞控制相关的概念。
TCP 拥塞控制的目标是最大化利用网络上瓶颈链路的带宽,那首要目标就是要测量带宽。
网络链路就像水管,要想用满这条水管,最好的办法就是给这根水管灌满水,灌满了就能得到这样一个公式:水管的容积 = 水管粗细 × 水管长度 换成网络的理解,也就是:网络链路上能容纳的数据包数量 = 链路带宽 × 往返延迟,这也就是带宽延迟积。
经典的 TCP 拥塞算法当想测量带宽延迟积的话也就是拼命往连接上写数据,一直写到开始丢包,这个时候认为达到了带宽延迟积的上限,再除以 RTT 就能算出来带宽。
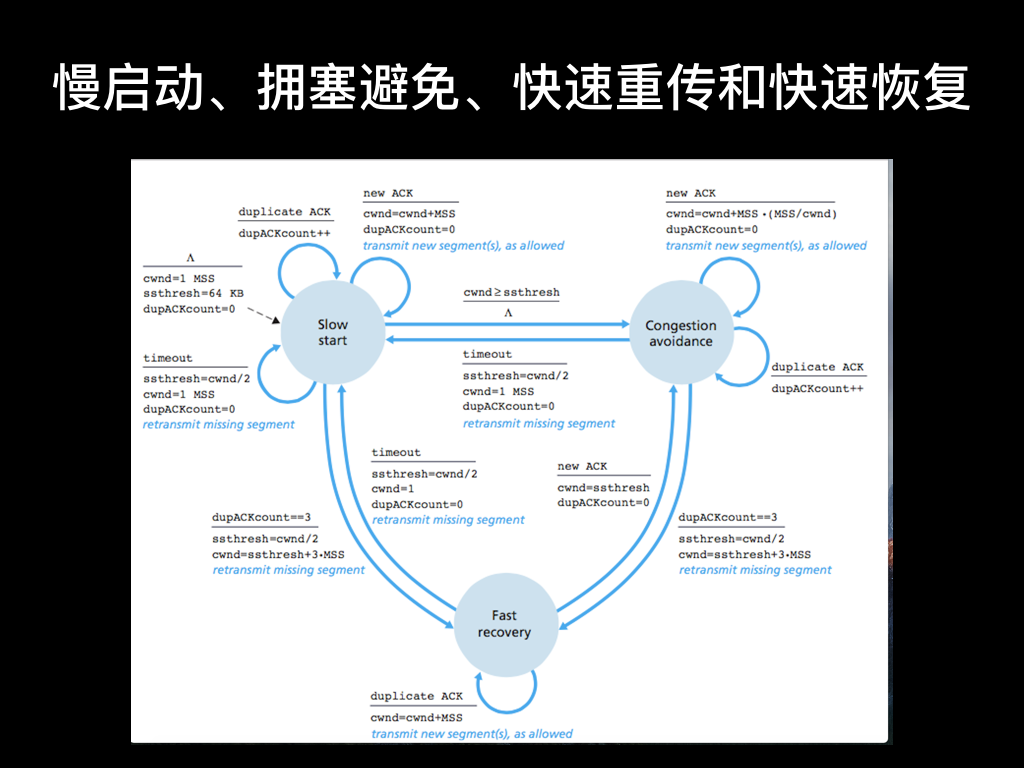
经典的 TCP 的拥塞控制由 4 个核心的算法组成:慢启动、拥塞避免、快速重传和快速恢复。图中的状态切换非常复杂,我捡最重要的描述一下。
- 慢启动的主要思路的探测网路的拥塞程度,每当报文被确认的时候,发送窗口就增大一倍,当发送窗口大于慢启动阈值启动过程结束,进入拥塞避免阶段
- 进入拥塞避免状态后发送窗口是线性增长不再指数增长
- 不管是在上面说的慢启动还是拥塞避免的状态,只要判断发送方出现丢包,就会将慢启动阈值设为当前发送窗口的一半,发送窗口值设为初始窗口大小,再重新进入慢启动
还有一条比较重要的线是快速重传和快速恢复:
- 快速重传指 TCP 在收到一个乱序的报文段时,会立即发送一个重复的 ACK,并且这个 ACK 不会被延迟,如果连续收到 3 个或 3 个以上重复的 ACK,TCP 会判定报文段丢失,需要重新传
- 快速恢复是指快速重传后直接进入拥塞避免阶段而非慢启动阶段
- 这部分的思路是能收到三次重复的 ACK,虽然有丢包但也说明网络状况不那么糟糕,所以跳过慢启动状态,直接从拥塞避免状态开始,发送窗口也降得少一些。
这两部分的算法的都有一个预设的判断在里面,就是认为当发现丢包的时候就认为发送带宽已经被占满了,所以我们的 TCP 连接要主动地降低发送窗口降低发送速度,避免链路拥塞。
但根据我们刚才对无线网络的分析这个思路还成立吗?如果是 WI-FI 的信道被强占了,可能等几秒你又能抢到空闲了,这个时候你的带宽是充足的,但你的 TCP 连接可能已经开始了慢启动,你要等好几个包的传输才能达到理论带宽。如果是蜂窝网络,你可能在行驶的地铁上刚好某段信号强度较弱,这个时候 TCP 开始慢启动,然后等信号好了你还是要等待 TCP 慢启动完成。如果是时延较长的网络,慢启动带来的影响会更大,要等待更长的时间来恢复。
其实 TCP 算法也不算错,至少开始慢启动的时刻确实理论带宽是低的,问题是 TCP 的慢启动策略还是太过保守,不能适应信号有一定波动的网络。
下面我给大家介绍另外两种比较有意思的拥塞控制算法,对这个问题分别给出了自己的答案。

第一种是 KCP,大家在 Github 搜一搜应该能搜到。目前在科学上网领域比较火的,另外的网易的几个视频直播项目和几个商业游戏中有使用。
它主要改进的点是计算超时更保守、丢包选择重传、不延迟 ACK、不退让流控。跟 TCP 相比牺牲了部分公平性,在传输小数据的时候更加激进,它在 Readme 中的介绍是浪费以 10%-20% 的带宽的代价,换取平均延迟降低 30%-40%。在传输数据量小而且在对延迟要求尽量低的网络条件下,这个协议比较粗暴,但也足够好用。

当大家都意识到丢包不再表示拥塞的时候,Google 的大佬们又提出了 BBR 拥塞控制算法。
根据定义当网络上的包数大于带宽延迟积时,就出现了拥塞。所以重点就在于如何准确地测量出瓶颈链路的带宽和整个链路的传播时延。
BBR 测量带宽和延迟的方法是交替测量带宽和延迟,用一段时间内的带宽最大值和延迟最小值作为估计值,所以有少量的丢包不会影响到带宽延迟积的计算,理论上在丢包率较高的的线路上使用 BBR 会比传统的 TCP 拥塞控制算法会更能充分利用带宽。
而 BBR 也不再像传统的 TCP 拥塞算法一样拼命地往链路上写数据,所以链路上的堵在各个路由缓冲区的数据包会更少,延迟也会有降低。

TCP 协议太复杂了,这里没法对所有的细节面面俱到,我们只总结了对性能影响比较大的几个因素:
第一个前面没有描述,但也是显而易见的。请求数据包最好能一次就发出去,移动网络下 RTT 可能要数百毫秒甚至可能都比后端的接口响应时间都要长,不然的话就要等一个 RTT 或者几个 RTT 后数据包收到服务端的 ACK 报文后才能继续发,这样的话就等太久了。
TCP KeepAlive 前面讲 Reachability 的时候也描述过,就不再赘述了。
剩下的几项我们前面也都有讨论,分别是尽量复用连接,启用 TCP Fast Open 和启用一些对丢包容忍度高或做过优化的拥塞控制算法。

HTTP 1.1 协议比较简单了,我们之前做过一些对比实验,比如:
- HTTP 长连接与短连接,在不同延迟下性能对比
- HTTP Pipeline 与并发短连接,在不同延迟下性能对比
- HTTP 不同请求响应大小,在不同带宽下对响应时间影响
- HTTP 并发连接,在不同的带宽下响应时间对比
- HTTP 在不同丢包率下对响应时间的影响
也得到了一些结论,也都挺符合直接的,没有太多需要额外解释的。
这里我总结一下就是:开启 Keepalive、开启 Pipeline、连接保活和预建连接。
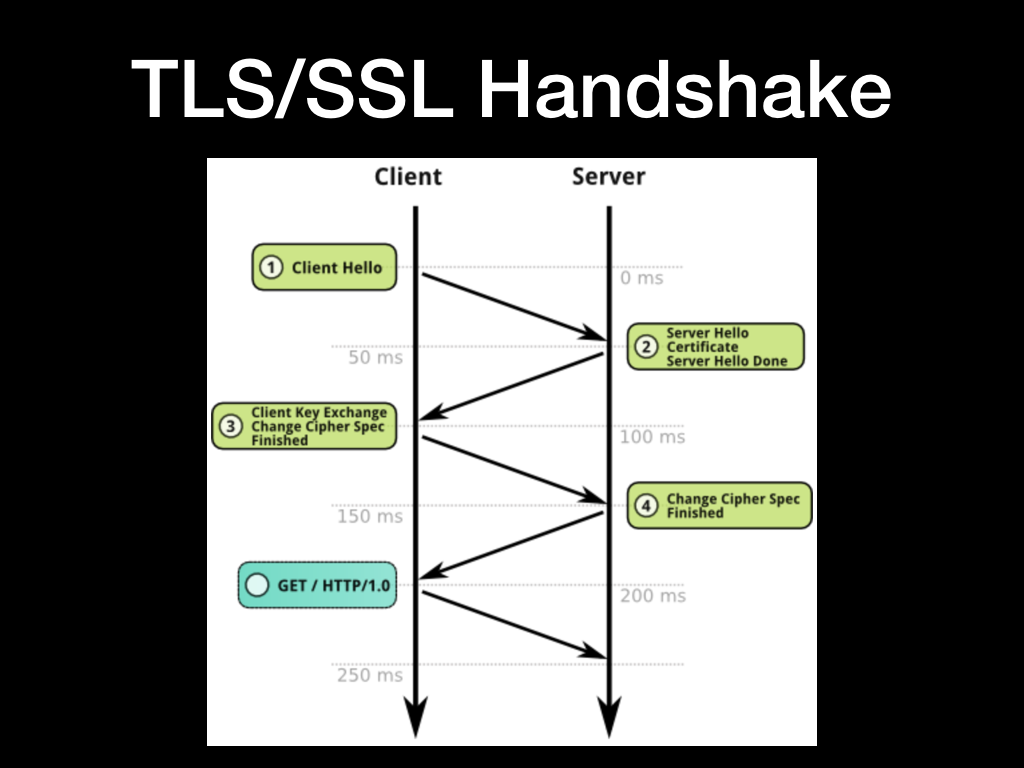
前面我们看了一个 Chrome 加载的时序图,其中 SSL 的握手花了非常久的时间,为什么呢?
SSL 层在 TCP 层之上,在完成 TCP 的握手之后开始传输 SSL 加密数据。SSL 层还需要握手,中间有数次 RTT 的数据传输,还有证书的交换,在丢包率高的网络下还可能发生重传。HTTPS 连接的初始化确实会比 HTTP 慢很多。
这里我们大致看一下 SSL 握手的流程:
- 客户端向服务端发送 Client Hello 消息,消息中包含了 SSL 协议的版本号,客户端支持的加密算法列表以及一些其他 SSL 可选项
- 服务端从客户端提供的算法列表中选择一个做为后续内容加密的算法,并向客户端发送服务端的证书
- 客户端校验服务端提供的证书,并向服务端发送加密的对称加密 Key
- 服务端校验客户端发送过来的相关信息并发送完成消息
- 客户端开始和服务端在建立加密通道上进行数据交换
但这两次 RTT 时间确实有点太长了,如果客户端到服务端的延迟是 50ms 那就至少需要 200ms 后客户端才能发出请求。
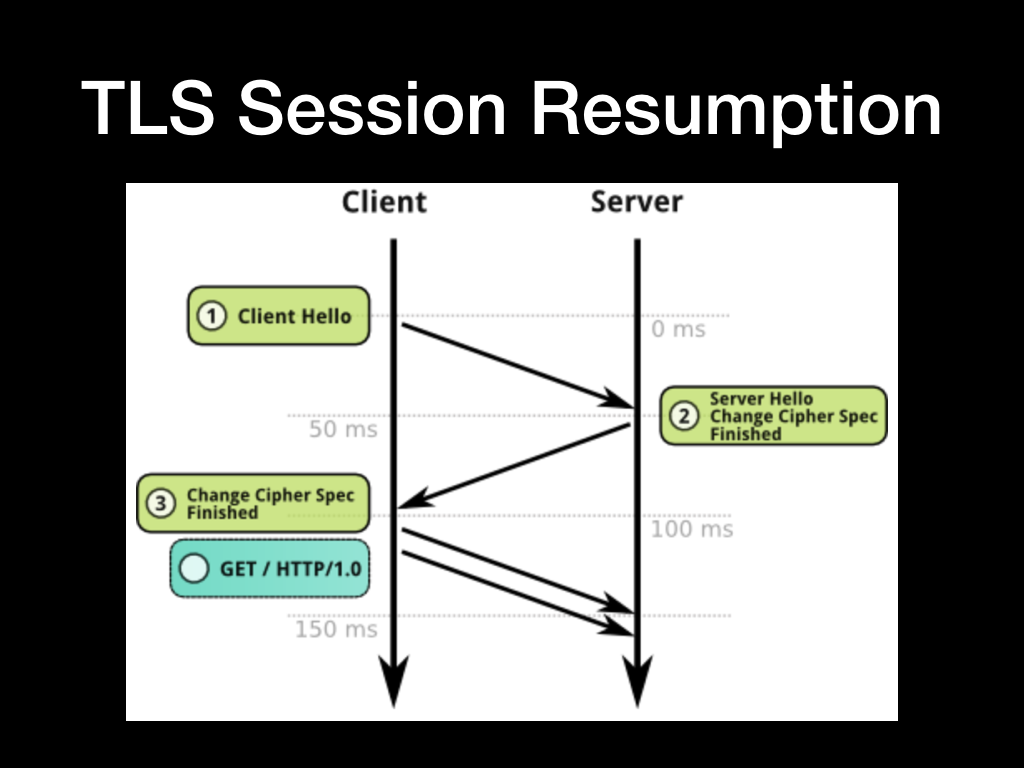
TLS 是有会话的概念的,会话中包含了协商好的加密算法和对称加密 Key 的信息,所以可以通过复用 Session 来减少握手次数。
Session 的存储方式也有两种,一种是叫 Session ID 是内容存储在服务端的 Session Cache 中的,另一种是叫 Session Ticket 是用服务端秘钥加密然后存储在客户端中的。建议优先使用 Session Ticket 方式来复用会话,Session Cache 可能会遇到多节点会话信息存储不共享和遇到服务端 Sesssion Cache 空间不足的问题难横向扩展,不过需要注意保证服务端密钥的安全。
我们说回来,看一下当复用 Session 的时候握手的流程是怎样的
- 客户端发送 Client Hello,并在 SSL 拓展中带上复用 Session ID 或者 Session Ticket
- 服务端发送 Sever Hello,并向客户端确认 Session 和加密算法
- 客户端收到确认后就可以在加密通道上交换数据了
这样的话 SSL 握手就减少到一个 RTT 了。
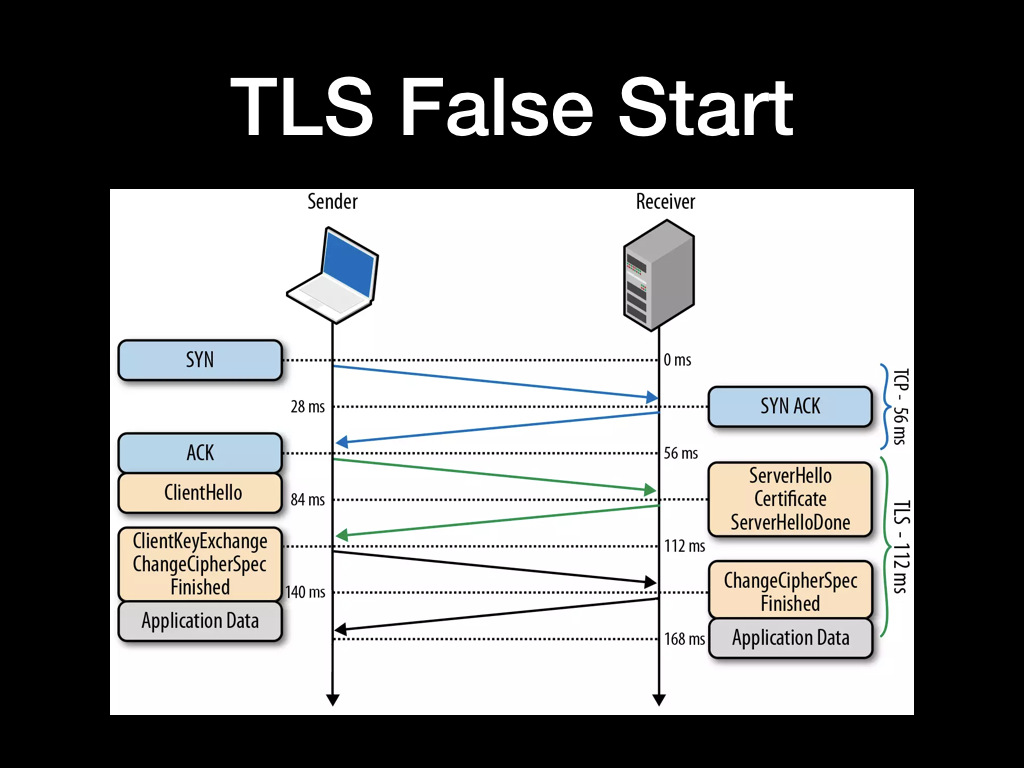
除了 SSL 会话复用以外,还有 TLS False Start 选项也可以达到类似的 1 RTT 的效果。
TLS False Start 是指客户端在确认使用的加密套件和加密 Key 的同时发送应用数据,服务端在 SSL 握手完成时直接返回应用数据。这样,应用数据的发送实际上并未等到握手全部完成,所以也称为抢跑。
跟 Session 复用相比区别不算太大,但 TLS False Start 会多传输一个证书,如果证书大小优化不好的话传输可能会更加耗时。
TCP 握手我们能优化到 0 RTT,那 TLS 的 1 RTT 的握手时间还能继续优化吗?

答案是能,但这个 feature 目前还在 TLS 1.3 的草稿中。微信自己开发了一个 TLS 套件叫 MMTLS,也做到了 0 RTT。今天时间有限,我们就不在这里过多叙述了,有兴趣的同学可以自行查阅相关的资料。

这里我们刚才介绍了 TLS 会话的复用和 TLS False Start 选项。剩下的还可以优化证书链大小,最好是「站点证书 - 中间证书 - 根证书」三级,可以减少证书的大小,避免分包,还可以调整 TLS Record Size 和使用椭圆曲线加密算法的证书等等。
TLS 是一套很复杂加密的协议,还有很多的设置可以去调优,这里我就抛砖引玉先只详细介绍这么多。

我们接着看 HTTP/2。HTTP 2 没有改变 HTTP 协议的语义,但把底层传输机制全改了。
HTTP/2 采用二进制格式传输数据,而不是 HTTP/1.1 的文本格式,二进制格式在协议的解析和优化扩展上带来更多的优势。
所以 HTTP/2 对请求 Header 部分才好进行压缩传输。Header 的压缩是连接的两端共同维护了一份动态索引,当 Header 的 key value 出现一次后就能被索引和压缩。这样的话如果连接能一直保持复用,Header 中的重复 key 都能被压缩,非常好用。
多路复用就是所有的请求都是通过一个 TCP 连接并发完成。HTTP/1.1 虽然通过 Pipeline 也能并发请求,但是多个请求之间的响应会被阻塞的,所以 Pipeline 至今也没有被普及,而 HTTP/2 做到了真正的并发请求,同时还支持优先级。
HTTP/2 相对 HTTP/1.1 提升巨大,所以我们的相关域名有条件的话应该都尽量迁移到 HTTP/2。

前面我们总结了很多协议层上的优化要点,往往我们开了一堆优化选项才能优化下来一两个 RTT。但业务一不注意,Duang 十来个 RTT 就没了。这里上面我总结了几点,但其实核心意思都一样,尽量少传输数据。
今天的分享就是这些内容,PPT 中大量参考了 《High Performance Browser Networking》(译《 Web 性能权威指南》) 书中的内容,同时还引用了之前做的移动网络性能调研的一些数据,还有大量的知乎、维基百科等等资料,谢谢大家。